Unspoken tips to master Apache Flink
Background
I spent my vast majority of my 7-month internship at Grab building real-time data stream processing applications. This involved learning, understanding, experimenting with (and of course, breaking) Apache Flink using Scala. I've compiled the following insights that are sure to enhance the daily experience for both novice and seasoned users alike.
Input Data
When dealing with such large-scale real-time systems that process user generated data, anything that can go wrong will go wrong. It is highly recommended to ensure proper clean up and filtering of input data streams, as any unexpected edge cases or values unaccounted for would throw exceptions and cause the flink job to fail. Some common strategies to achieve this would be to
- Check for null or missing values
- Put up a default branch in
if-else/switchstatements with default actions like discarding- Implement a check to ensure validity of unsuspecting fields like userID, coordinates, etc as values like 0 may be used in certain systems for internal api calls
Structure
It is a common and recommended practice is to encapsulate all logic including pre-processing into the buildStream method of the corresponding
XXXStreamobject. This enables simpler end-to-end testing of the app's logic.
Config classes, that load application parameters from continuous delivery platforms/pipelines, are often used to store and access these parameters. Do note that extending such an AppConfig class doesn't work well with unit testing, as these parameters will not be available during testing runtime. If you intend to test a
XXXStreamobject as a whole, it is advised to pass all config values as arguments instead.
object Main extends TLogging with AppConfig {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = FlinkEnv
.setGlobalJobParams(params)
.getEnv
val sourceStreamA: DataStream[InputProtoClass] = KafkaSource.getNoWM[InputProtoClass](env, kafkaSourceA)
val configStream: DataStream[ConfigClass] = ConfigMappingFromFileLoader.build(env, configFilePath)
val xxxStream: DataStream[OutputProtoClass] = XXXStream.buildStream(sourceStreamA, configStream, configValue1, configValue2)
SinkUtils.addKafkaProtoSink[OutputProtoClass](xxxStream, xxxStreamSink)
env.execute()
}
}
Operator State
UID
It is highly recommended to specify the uid for stateful operators to ensure proper restoration of state from savepoints. This is can be achieved by calling the
.uid(string)method on the operator. It is a common practice to use the same value for.name()and.uid()for simplicity and readability.
someStream
.keyBy(_.id)
.flatMap(new CustomRichFlatMapFunction())
.name("operator-identifier")
.uid("operator-identifier")
Schema Evolution
Out of the box, Flink only offers state schema evolution for POJO and Avro types. For a Scala data type to be considered POJO type, it has to
- Be a regular (
case) public standalone class (no non-static inner class)- Contain only mutable fields.
- Have a public no-argument constructor
- All non-static, non-transient fields in the class (and all superclasses) are either public (and nonfinal) or have a public getter- and a setter- method that follows the Java beans naming conventions for getters and setters.
As an additional test, you can check if your class is considered as POJO by Flink if it uses the PojoSerializer as a result of the following expression
createTypeInformation[XXXPojo].createSerializer(env.getConfig).getClass.getSimpleName
Flink supports evolving schema of POJO types, based on the following set of rules:
- Fields can be removed. Once removed, the previous value for the removed field will be dropped in future checkpoints and savepoints.
- When evolving the schema to remove fields of complex/POJO type, it has to be done in two migration steps
- Remove the field but retain the field's class definition for serializer snapshot to be initialised properly.
- Remove the field's class definition.
- New fields can be added. The new field will be initialized to the default value for its type, as defined by Java.
- Declared fields types cannot change.
- Class name of the POJO type cannot change, including the namespace of the class.
Watermarks
Propagation through Operators
- Basic transformations like Map, FlatMap, etc all retain the assigned timestamp for all produced/transformed objects.
- Results of Window functions like Reduce, Aggregate, ProcessWindow get assigned the processed window's inclusive end timestamp (in milliseconds)
- Resultant stream of
(Keyed)BroadcastProcessFunctionhas no watermarks or timestamps assigned. You would have to manually assign them again.
Periodic Streams
For periodic streams i.e. stream with periodic production of data at the end of every minute/hour, watermarks are not produced in the interval between data due to the very nature of how watermarks are created and used. This causes issues when using windows or timers downstream as there is no watermark generated to mark the end of a window since there are no events till the next period to indicate so.
One solution to this problem is to define a custom
PeriodicStreamWatermarkGenerator- when there are no new elements seen forwaitThresholdMs, watermarks signalling the end of the currentperiodDurationMsperiod will be produced. You can simply pass the parameters to the watermark generator or you can further customise this to suit your use cases.
Joining Streams
- Window CoGroup is the equivalent of outer join on a time window with matching keys
- All the elements of the both streams that fall in the window with matching keys are passed to the
(flat)coGroupfunction in one call i.e. all matching elements are processed at once.
- All the elements of the both streams that fall in the window with matching keys are passed to the
- Window Join is the equivalent of inner join on a time window with matching keys
- Each element of stream A is paired with each element of stream B of the same window and matching key in a different call to the
(flat)joinfunction i.e. each matching pair is processed individually
- Each element of stream A is paired with each element of stream B of the same window and matching key in a different call to the
Windowing
- Where possible,
ReduceFunctionandAggregateFunctionare recommended overProcessWindowFunction; they are more efficient due to incremental aggregation of records as they enter the windows.- You can also enable Incremental Aggregation with ProcessWindowFunction to have the advantage of incremental aggregation while having access to additional window metadata.
- The onTimer method available in process functions like
ProcessFunctionandKeyedProcessFunction, offer a higher level of control and allow more complex operations when compared to regular windows.- It is also a good alternative to Sliding Windows when the slide is very small compared to the window duration as it reduces the memory usage by not duplicating the events.
- In the case of large number of keys, timers can be coalesced by rounding them to the nearest minute/hour
Sink
Explicitly defining keys when sinking to a kafka topic results in a more even load across the partitions of the topics. Balanced topic partitions result in balanced table partitions downstream when ingested into data warehouses, thereby leading to more efficient and faster query times. Its important to choose a well distributed key for this purpose. Additional info on Kafka partitioning.
Unit Tests
When testing user-defined functions (UDF) like
ProcessFunctionorRichFlatMapFunction, it is advised to use Test Harnesses
- Test Harness tend to be much faster and less resource intensive than creating and executing a new flink environment.
- Test harnesses for ProcessFunction and WindowOperator also exist.
- Test harnesses also provide a deterministic way to test operators by providing precise control of element processing and timestamp progression.
Monitoring
Flink Job
- When running Flink sessions on Kubernetes, apart from monitoring the job via a CD platform, you can also inspect the job by forwarding the job manager instance to port 8081 and using the Flink Web UI locally.
kubectl port-forward -n8081
- For debugging deployments using IntelliJ's Step and Debug tool, set up a configuration on IntelliJ as shown below.
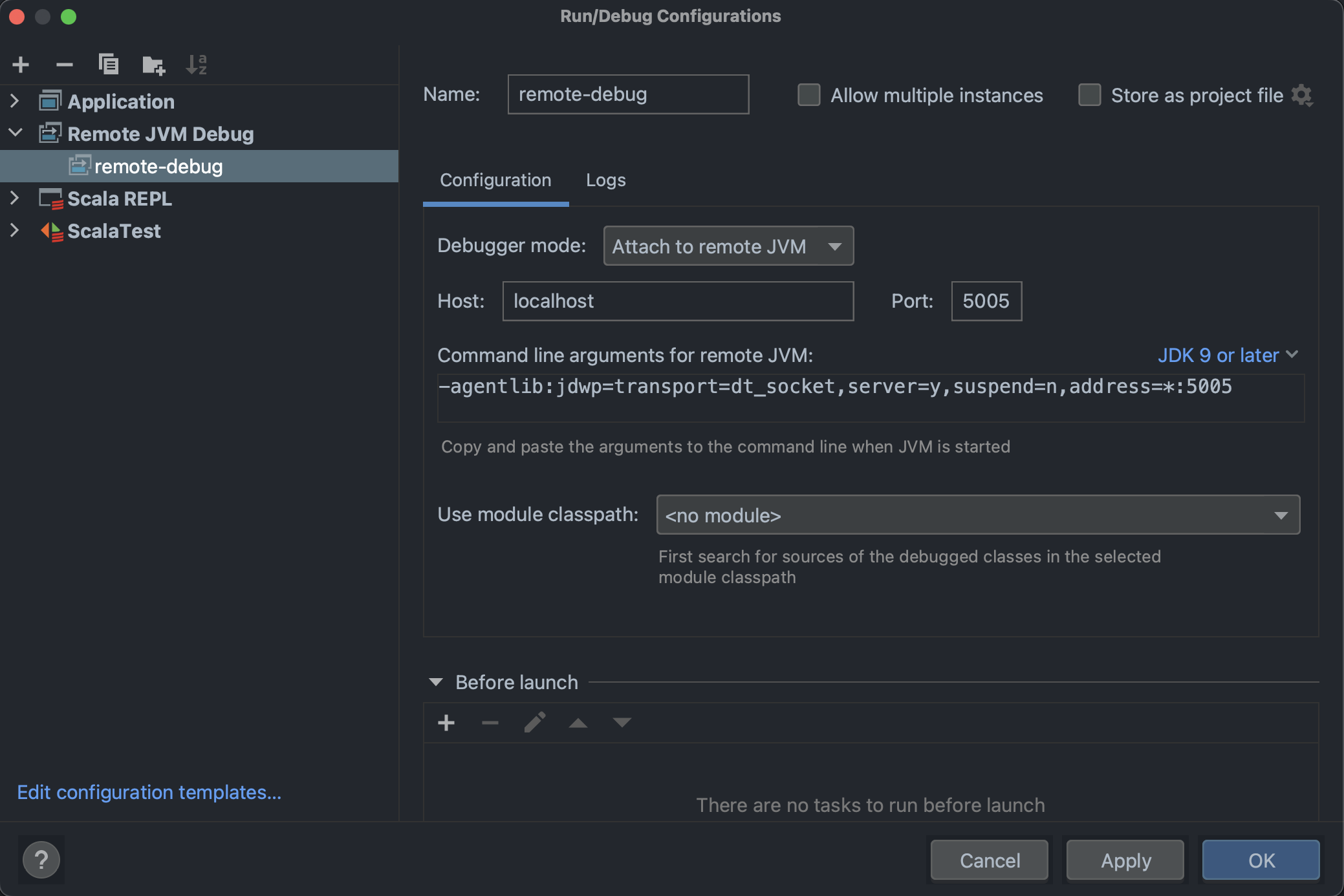
- Then port forward the task manager instance to port 5005. Run the debug configuration and place breakpoints to inspect.
kubectl port-forward -n5005:5005 - Note: It is strongly advised to debug on non-production environments only, as halting the program for more than a few seconds often leads to task failure and subsequent restarts for recovery.
DataDog
To enable reporting of distribution metrics with advanced and dynamic percentile queries like p25, p75 or p80, use
distributionfor reporting.