Multiclass Weed Identification
DeepWeeds CNN - Repo
Part of a team project for Machine Learning (CS3244) course taken in AY 2022/23 Sem 1.
Background
Our team (of 5 members) was tasked with choosing a dataset from a given list and frame a motivated problem statement around that dataset. We are then intended to spend the next 10 weeks exploring the problem using various machine learning techniques. As part of this project, I took upon the task of exploring the problem using Convolutional Neural Networks (CNN), while other team members explored methods such as KNN, Decision Trees, SVM and Tranfer Learning.
You can additionally also checkout the project proposal.
Dataset - Repo, Kaggle, TFDS

The DeepWeeds dataset consists of 17,509 unique 256x256 colour images in 9 classes. There are 15,007 training images and 2,501 test images. These images were collected in situ from eight rangeland environments across northern Australia.
Preprocessing and Augmentation
- The data was already cleaned, formatted and labelled appropriately, prompting no further cleaning.
- The labelled dataset was randomly split into 3 categories for train, validation and testing in 8:1:1 ratio. All models were trained using the same initial split.
- To improve the visibility of important features and reduce noise in the images, we employed a three step processing technique.
- Histogram equalisation
- HSV mask for slicing greens
- Gabor filter

- Since the negative class (7000+ images) was much bigger than the positive classes (900 each), each positive class was augmented over itself 4 more times with random rotation and flips.
Models
We used micro-averaged recall score on the validation set as the performance measure - to account for the imbalanced class sizes as well as high cost consequence of misclassifying an instance as negative.
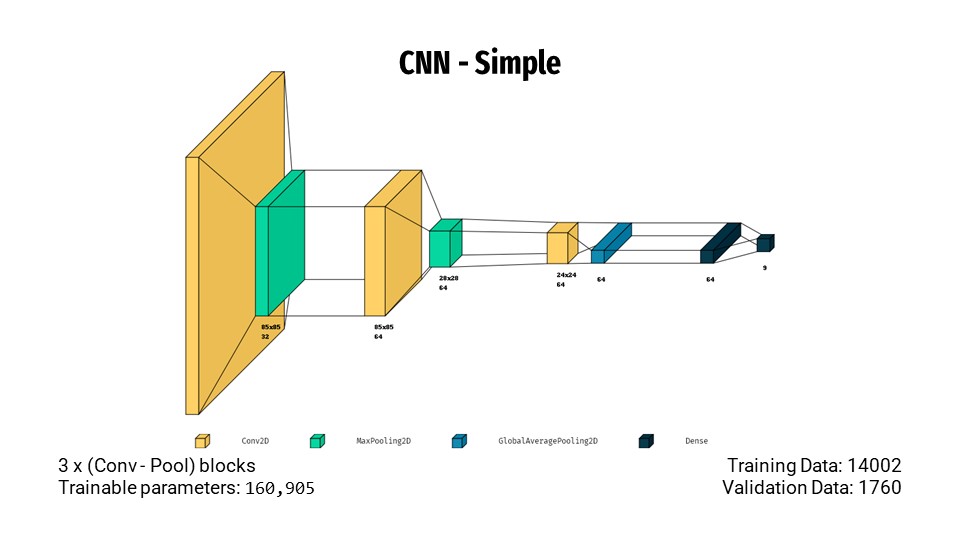
- Starting off with a simple network, we have 3 convolutional-pooling blocks followed by dense layers. This model trained with non-augmented data gave a recall score of 66.78%.
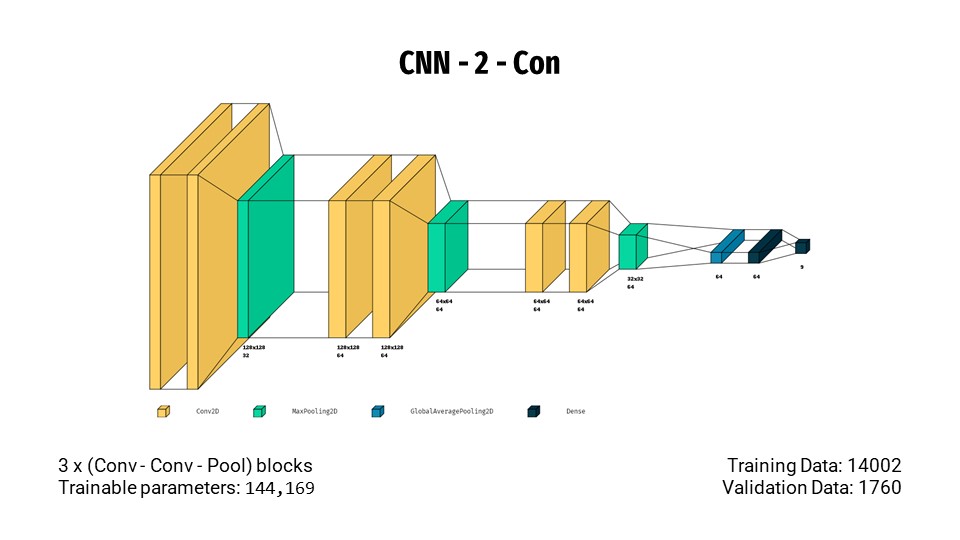
- Building upon the previous model and adding an additional convolutional layer to each block, we increase the recall score to 75.38%.
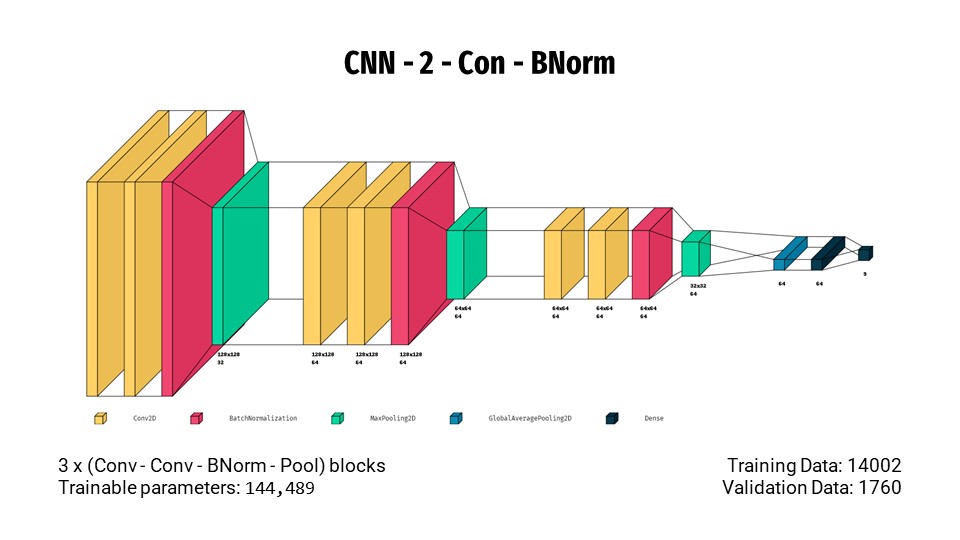
- Adding a batch normalisation layer to each block unfortunately bumps the recall score slightly down to 73.18%.
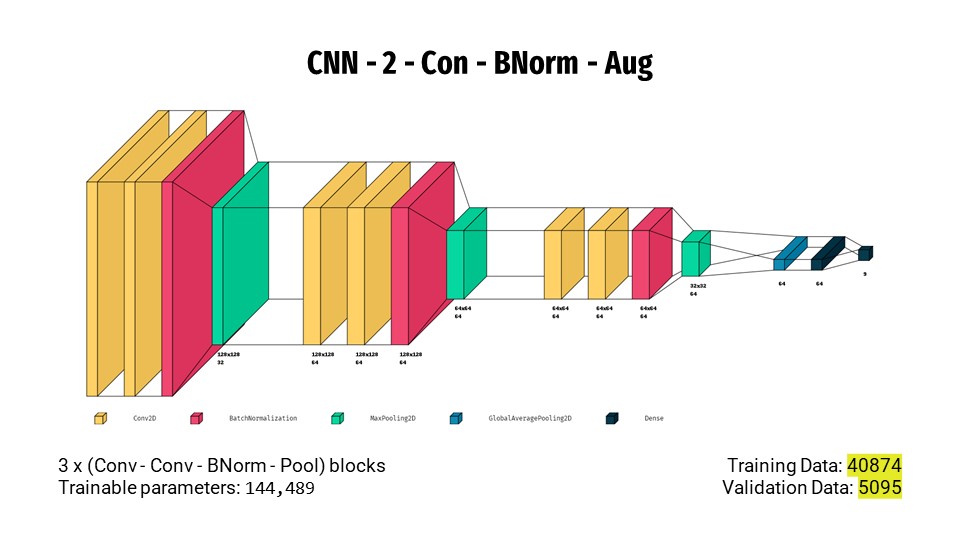
- Training the same model again on augmented data, we see a massive rise in the recall score to 92.23%.
- Finally, we increase the number of (conv-conv-bnorm-pooling) blocks to 5 and use augmented training data to get a sweet recall score of 93.66%.
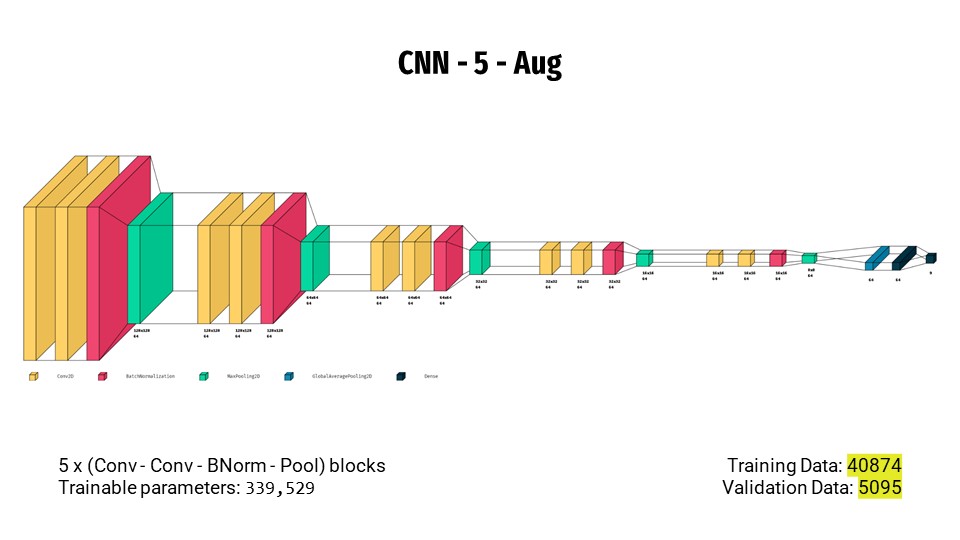
Not good enough...
The problem with the last model above is that, while it is good at classifying weed species, it is unable to detect the presence/absence of weeds accurately. This is measured using N-Recall score i.e. recall score calculated on the negative class. CNN-5-Aug only had a N-Recall score of 65.7%.
At this point, my teammate Bryan used transfer learning to build a really good weed detector with a N-Recall score 94.9%.
I came up with the crazy idea of using the output label probabilites from both of these models as inputs into a dense neural network and use the outputs from this ensemble network to make the final prediction.
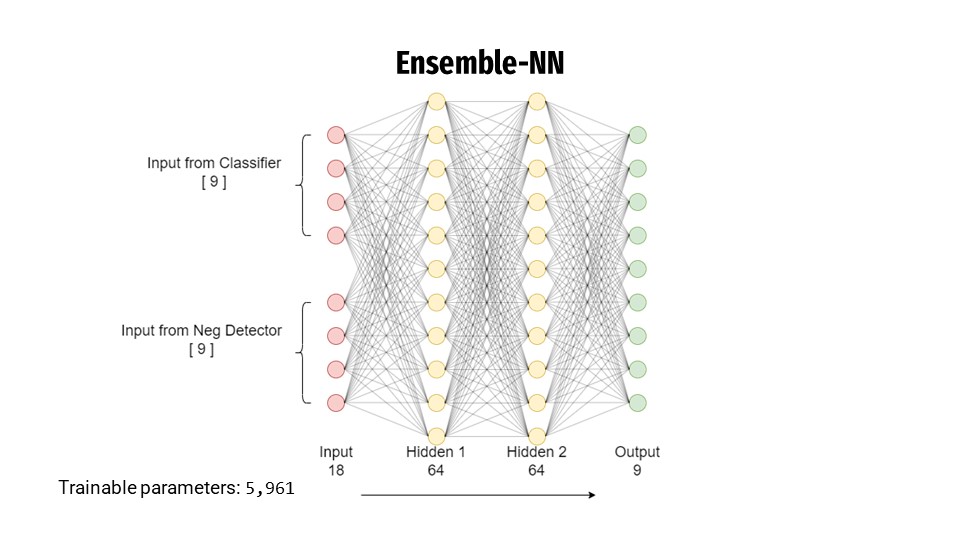
This ensemble model had the best validation accuracy at 90.84% and best testing accuracy at 91.70%.
Put together using
- Tensorflow - Open-source library for machine learning
- Keras - High-level neural network library on top of TensorFlow
- Seaborn - Python data visualization library
- Google Colab - Hosted Jupyter Notebook service with free access to GPUs
Teamwork makes the dreamwork
- Bryan Tee Pak Hong
- Cheong Yee Ming
- Cheah Yan (Xie Yan)
- Kong Fanji
- Yeluri Ketan